On Linux, we can read CSV files using Bash commands.
But it can get very complicated, very quickly.
We’ll lend a hand.
What Is a CSV File?
A Comma Separated Values file is atext file that holds tabulated data.
CSV is a key in of delimited data.

Related:What Is a CSV File, and How Do I Open It?
If an program has import and export functions, it’ll almost always support CSV.
CSV files are human-readable.
For example, you might export the data from anSQLitedatabase and open it inLibreOffice Calc.
However, even CSV can become complicated.
Want to have a comma in a data field?
That field needs to have quotation marks "
" wrapped around it.
To include quotation marks in a field each quotation mark needs to be entered twice.
Some Sample Data
you could easily generate some sample CSV data, using sites likeOnline Data Generator.

you’re able to define the fields you want and choose how many rows of data you want.
Your data is generated using realistic dummy values and downloaded to your rig.
Our sample file has one.
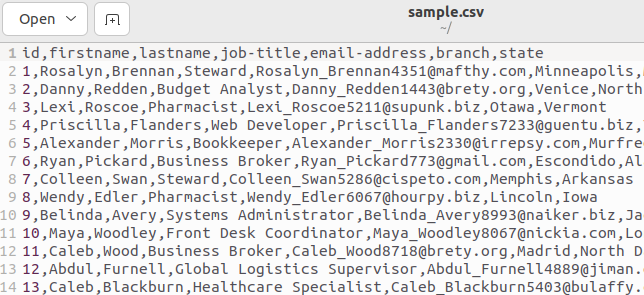
Here’s the top of our file:
The first line holds the field names as comma-separated values.
Copy this script into an editor, and save it to a file called “field.sh.”
Let’s break it down.
Related:How to Process a File Line by Line in a Linux Bash Script
We’re using awhileloop.
As long as thewhileloop condition resolves to true, the body of thewhileloop will be executed.
The body of the loop is quite simple.

A collection ofechostatements are used to print the values of some variables to the terminal window.
Thewhileloop condition is more interesting than the body of the loop.
The IFS is an environment variable.

Thereadcommand refers to its value when parsing sequences of text.
We’re using thereadcommand’s-r(retain backslashes) option to ignore any backslashes that may be in the data.
They’ll be treated as regular characters.

The text that thereadcommand parses is stored in a set of variables named after the CSV fields.
The data is obtained as the output fromthetailcommand.
We’re usingtailbecause it gives us a simple way to skip over the header line of the CSV file.

The-n +2(line number) option tellstailto start reading at line number two.
The<(…)construct is calledprocess substitution.
It causes Bash to accept the output of a process as though it were coming from a file descriptor.
This is then redirected into thewhileloop, providing the text that thereadcommand will parse.
Make the script executable usingthechmodcommand.
You’ll need to do this each time you copy a script from this article.
Substitute the name of the appropriate script in each case.
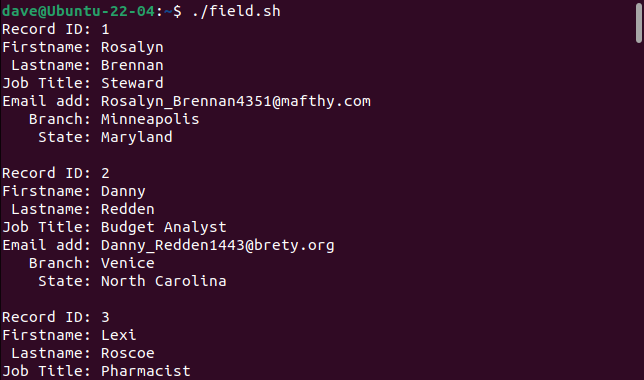
Each record is printed as a set of fields.
Selecting Fields
Perhaps we don’t want or need to retrieve every field.
We can obtain a selection of fields by incorporatingthecutcommand.
This script is called “select.sh.”
We’re using the-d(delimiter) option to tellcutto use commas “,” as the delimiter.
The-f(field) option tellscutwe want fields one, four, six, and seven.
Those four fields are read into four variables, which get printed in the body of thewhileloop.
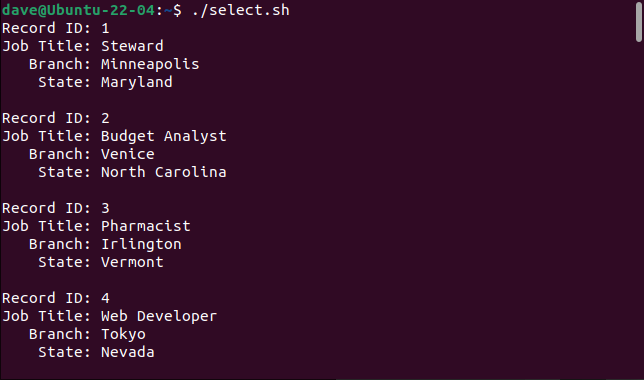
This is what we get when we initiate the script.

So Far, So Good.
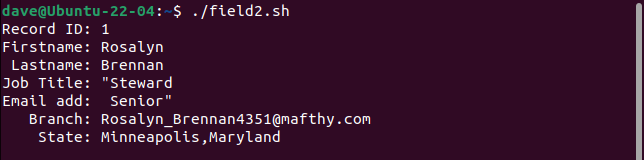
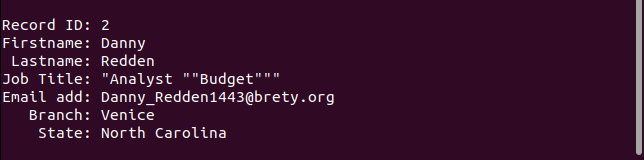
The first record splits the job-title field into two fields, treating the second part as the email address.
Every field after this is shifted one place to the right.
The last field contains both thebranchand thestatevalues.
The second record retains all quotation marks.
It should only have a single pair of quotation marks around the word “Budget.”
The third record actually handles the missing field as it should.
The email address is missing, but everything else is as it should be.
Counterintuitively, for a simple data format, it is very difficult to write a robust general-case CSV parser.
Tools likeawkwill let you get close, but there are always edge cases and exceptions that slip through.
One is to use a purpose-designed tool to manipulate and extract your data.
The second is to sanitize your data and replace problem scenarios such as embedded commas and quotation marks.
Your simple Bash parsers can then cope with the Bash-friendly CSV.
You’ll need to install it on your rig.
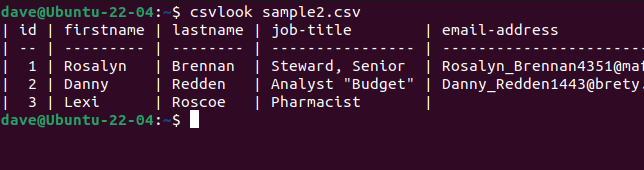
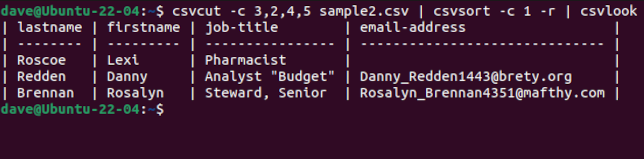
Let’s trycsvlookwith our problematic “sample2.csv” file.
All of the fields are correctly displayed.
This proves the problem isn’t the CSV.
The problem is our scripts are too simplistic to interpret the CSV correctly.
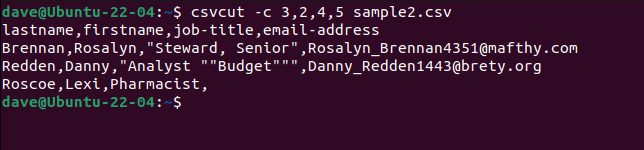
To select specific columns, use thecsvcutcommand.
All we need to do is put the field names or numbers in the order we want them.
These three commands are all equivalent.
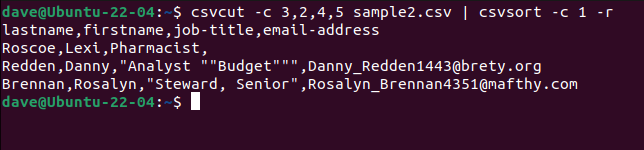
We can add thecsvsortcommand to sort the output by a field.
To make the output prettier we can feed it throughcsvlook.
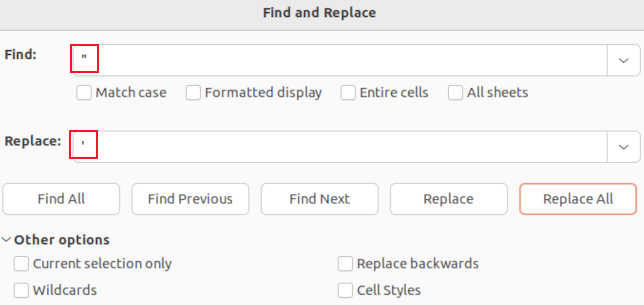
it’s possible for you to use the find and replace function to search for commas.
You won’t see the quotation marks around quoted fields.
The only quotation marks you’ll see are the embedded quotation marks inside field data.
These are shown as single quotation marks.
You’ll only change the data values of fields.
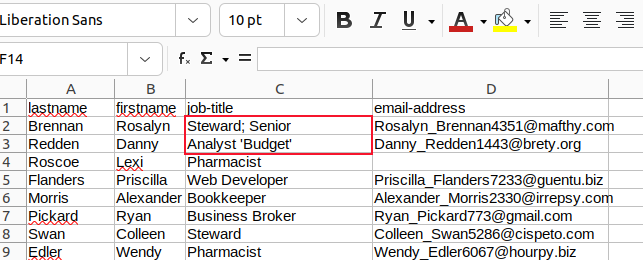
We changed all commas in fields with semicolons and all embedded quotation marks with apostrophes and saved our changes.
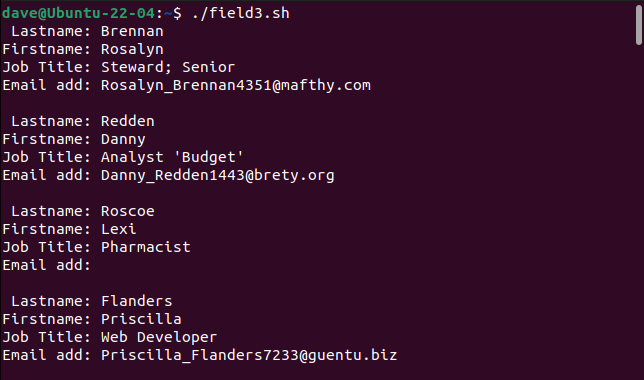
We then created a script called “field3.sh” to parse “sample3.csv.”
Our simple parser can now handle our previously problematic records.
Most applications that handle some form of data support importing and exporting CSV.
Knowing how to handle CSV—in a realistic and practical way—will stand you in good stead.
Related:9 Bash Script Examples to Get You Started on Linux
