Related
Quick Links
Computers store characters by mapping them to different binary values.
To display them properly, you gotta know how they were encoded.
The iconv command converts a file to a new encoding.
Images, text, music, video, and everything else are stored as binary data.
The software can then work backward and map the stored numerical values back to characters.
They’re easy to understand if we get the jargon straight.

Atypefaceis what a lot of peoplemistakenly call a font.
Regardless of the typeface, the numerical representation of the character remains the same.
All the characters in a single mapping are called thecharacter set.
Hannah Stryker / How-To Geek
Each character in a set has its own, fixed, unique, numerical value called acode point.
An important consideration is the number of bytes used to represent a single character.
The more bytes you use per character, the more characters you might include in the set.
The granddaddy of all single-byte character sets is theASCII standard.
By contrast, theUnicode standardcontains a total of 1,114,112 code points.
Such a large code space is required because Unicode tries to provide character mapping support for all human languages.

Using a fixed number of bytes to store code points is wasteful.
So, a code point may have to encode two types of data.
The advantage of a variable-length scheme is you only use the bytes you really need.
This is efficient, and results in smaller files.
The disadvantage is, the data is more complicated to read and parse.
And converting from one character set to another can become very difficult, very quickly.

Thats where the iconv command comes in.
It lists over 1100 different encodings, but many are aliases for the same thing.
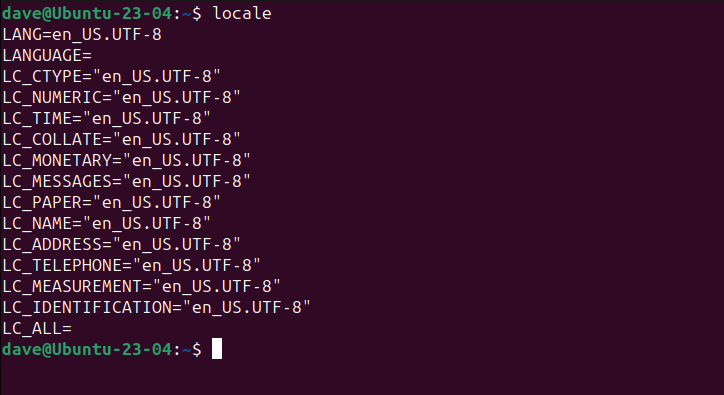
We can list all the supported encodings using the -l (list) option.
Well use iconv with STDIN to illustrate some points.
The first line says were using US English, and Unicode UTF-8 encoding.
Were going to convert this into ASCII.
Were using echo topipeour input text to iconv.
That fails at the first hurdle.
There is no equivalent character in US-ASCII for a, so the conversion is abandoned.
iconv uses zero-offset counting, so were told the problem occurred at position six.
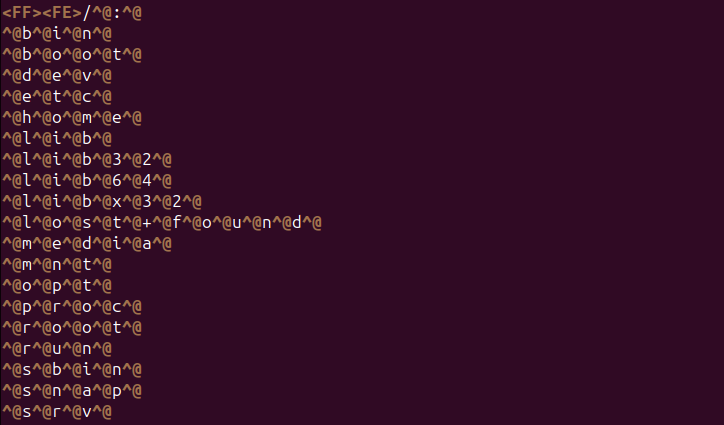
The command runs to completion now, but there are characters missing from the output.
If it cant manage that, it inserts a question mark ?
so you could easily see a character didn’t get converted.
This process is calledtransliteration, and to invoke it you append the string //TRANSLIT to the target encoding.
To find out the encoding pop in of the source file, we can use the file command.
Our input file is inUTF-16LEencoding.
We need to use the -o (output) option to name the output file.
We dont use an option to name the input filewe just tell iconv what it is called.
They arrive in all sorts of encodings.
Ive blessed iconv more than once for easily letting me work with those files on Linux.
